Autor: Alejandro Coucheiro, IPTC | Director: Javier Ferreiros López, IPTC.
Los reconocedores automáticos de habla ofrecen a día de hoy un rendimiento muy notable en múltiples y complicadas tareas. Esto ha propiciado su incorporación en aplicaciones de usuario que ya son usadas con cierta asiduidad, pudiendo realizar desde tareas tan simples como un dictado o búsquedas web, hasta más complejas como las que involucran diálogos para configurar, por ejemplo, dispositivos domésticos programables.
Las condiciones acústicas y lingüísticas del habla que sirve de entrada a estos sistemas pueden variar enormemente de una fuente a otra, lo cual exige un notable trabajo para mejorar los modelos acústicos y de lenguaje que estos sistemas emplean. Centrándonos en la parte lingüística, el esfuerzo se centra en cómo gestionar la gran cantidad de temáticas y dominios distintos que están presentes en el habla. Más allá de una solución de fuerza bruta, en la cual emplearíamos un vocabulario y un modelo de lenguaje gigantescos para tratar de enfrentarnos con cierto éxito a cualquiera de estos escenarios, resultan más interesantes los sistemas que pueden restringir sus capacidades de modelado para reconocer con gran precisión ciertos tópicos o dominios.
Una restricción del lenguaje que fuera variable en el tiempo, manteniendo una sintonización del modelo con las características del habla de cada momento, ofrecería a los sistemas de reconocimiento una capacidad de adaptación enfocada a alcanzar un rendimiento óptimo.
Este trabajo de tesis se centra en una adaptación automática y no supervisada al habla de cada momento, y que por tanto no requiera de una identificación explícita de las temática discutidas. En su lugar, se pretende que la adaptación esté dirigida por el vocabulario que está siendo empleado en el habla, para de este modo tratar de sintonizar convenientemente los diccionarios de los sistemas de reconocimiento.
Aparte de las palabras dentro-del-vocabulario (In-Vocabulary, IV) que pudiéramos transcribir del habla, nos interesan más las palabras que no estuvieran ya presentes en el vocabulario de los sistemas, conocidas como palabras fuera-del-vocabulario (Out-Of-Vocabulary, OOV), ya que su aparición puede indicar implícitamente cambios de tópico o dominio. Así, proponemos estrategias para resolver palabras OOV en el habla y, en último término, aprender su sintaxis y semántica para que puedan ser introducidas convenientemente en los sistemas de reconocimiento.
Tales estrategias pueden dividirse en dos niveles de operación, uno que funciona a un nivel estático y local, y otra que funciona a nivel dinámico y evolutivo. Las hemos llamado estrategia de Descubrimiento de Términos (Term Discovery, TD) y estrategia de vocabulario dinámico, respectivamente, y ambas interactúan en la manera que se indica en la figura.
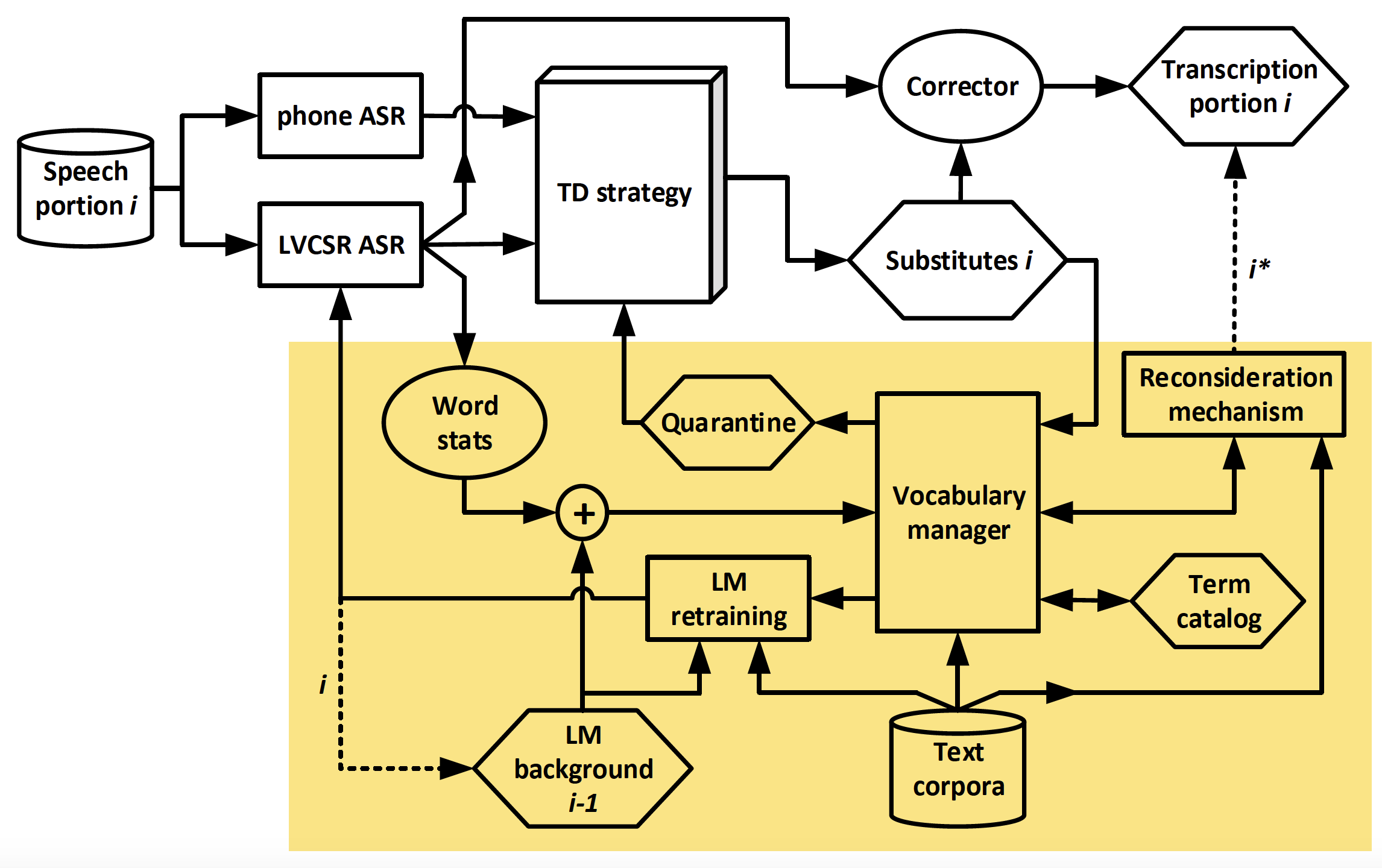
Los procesos involucrados en la estrategia TD se enumeran a continuación:
- Detección de palabras OOV que puedan aparecer en el habla de entrada.
- Búsqueda de candidatos de palabra para cada OOV detectada. Se emplea un esquema que efectúa dos tipos diferentes de búsquedas, una dirigida por las evidencias acústicas provistas por un sistema de reconocimiento de alófonos (Phone ASR en la figura), y otra dirigida por la semántica contextual observada.
- Corrección de la transcripción con el mejor candidato hallado (substitute), si lo hubiera.
Y con respecto a la estrategia de vocabulario dinámico, hemos propuesto una serie de procesos para ser ejecutados iterativamente según se precisen, y así reaccionar al habla que se esté procesando:
- Colección continua en un Term Catalog de los términos hallados por la estrategia TD.
- Selección de términos de entre todos los capturados antes, para su incorporación al vocabulario. También, selección de los términos IV menos interesantes, para que su eliminación. En cuanto a las palabras a añadir, verificamos si hay suficiente material de entrenamiento en fuentes externas sobre los nuevos términos (o si no, han de ser puestos cautelosamente en cuarentena), y asimismo podemos reconsiderar si las correcciones realizadas a la transcripción por un término fueron lo suficientemente fiables o no. Y en cuanto a las palabras a eliminar, nuestra valoración se basa tanto en cuáles de las palabras IV no están siendo utilizadas lo suficiente (gracias a las Word Statistics), como qué palabras no encajan del todo bien en el estado actual del modelo de lenguaje del sistema.
- Actualización del vocabulario y el modelo de lenguaje, considerando el conocimiento adquirido en fuentes externas acerca de los nuevos términos (módulo LM (Language Model) retraining de la figura).
Las estrategias propuestas han sido evaluadas en marcos de experimentación realistas, en los cuales hemos logrado mejoras significativas sobre los sistemas de referencia para ambas estrategias.
Newsletter marzo-abril 2020 PhD corner